Activation Patching#
📗 You can find an interactive Colab version of this tutorial here.
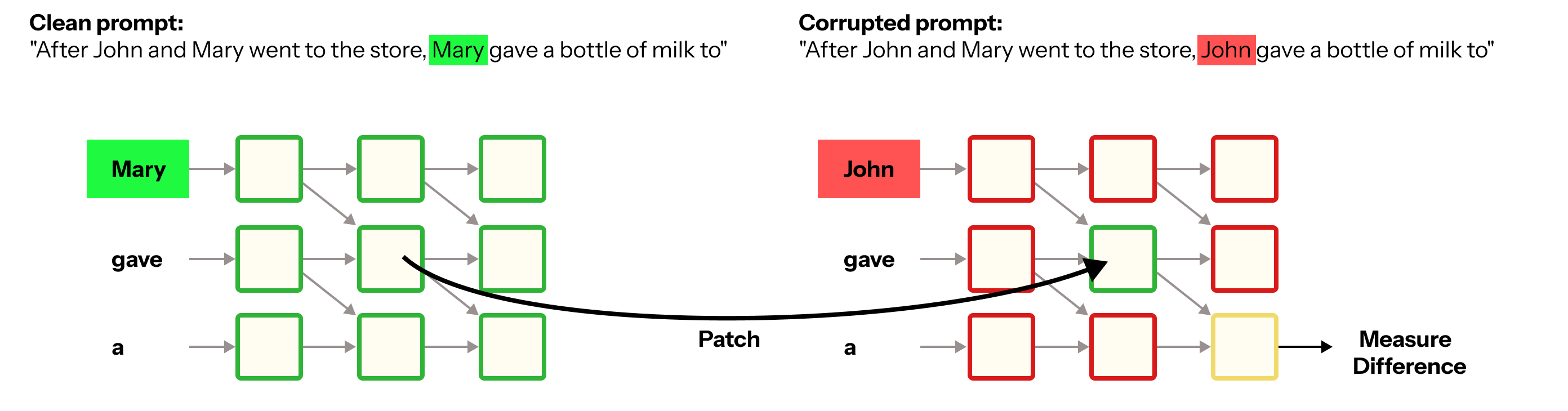
Activation patching is a technique used to understand how different parts of a model contribute to its behavior. In an activation patching experiment, we modify or “patch” the activations of certain model components and observe the impact on model output.
Activation patching experiments typically follow these steps:
Baseline Run: Run the model and record original activations.
Corrupted Run: Run the model with with a counterfactual (i.e., corrupted) prompt and record the difference in activations.
Patching: Replace activations at the model component of interest with alternate activations (or zeros, which is sometimes referred to as ablation).
By systematically testing different components this way, researchers can determine how information flows through the model. One common use case is circuit identification, where a circuit is a subgraph of a full model that is responsible for a specific and human-interpretable task (e.g., detecting whether an input is in English). Activation patching can help identify which model components are essential for model performance on a given task.
In this tutorial, we use nnsight to perform a simple activation patching experiment using an indirect object identification (IOI) task.
Note: IOI Task#
Activation patching was used to find the Indirect Object Identification (IOI) circuit in GPT-2 small. IOI is a natural language task in which a model predicts the indirect object in a sentence. IOI tasks typically involve identifying the indirect object from two names introduced in an initial dependent clause. One name (e.g. “Mary”) is the subject (S1), and the other name (e.g. “John”) is the indirect object (IO). In the main clause, a second occurrence of the subject (S2) typically performs an action involving the exchange of an item. The sentence always ends with the preposition “to,” and the task is to correctly complete it by identifying the non-repeated name (IO).
In this exercise, we will use the following ‘clean’ prompt:
"After John and Mary went to the store, Mary gave a bottle of milk to"
This prompt’s correct answer (and thus its indirect object) is: " John"
We will also use a corrupted prompt to test how activation patching works. This corrupted prompt will switch the identity of the indirect object, so we can test how the model responds to this change.
"After John and Mary went to the store, John gave a bottle of milk to"
This prompt’s correct answer (and thus its indirect object) is: " Mary"
Setup#
[1]:
try:
import google.colab
is_colab = True
except ImportError:
is_colab = False
if is_colab:
!pip install -U nnsight
[2]:
from IPython.display import clear_output
[3]:
import nnsight
from nnsight import CONFIG
/opt/anaconda3/envs/nnsight/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Let’s start with our imports:
[4]:
import plotly.express as px
import plotly.io as pio
pio.renderers.default = "colab" if is_colab else "plotly_mimetype+notebook_connected+colab+notebook"
from nnsight import LanguageModel, util
[5]:
# Load gpt2
model = LanguageModel("openai-community/gpt2", device_map="auto")
clear_output()
[6]:
print(model)
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-11): 12 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2SdpaAttention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
(generator): Generator(
(streamer): Streamer()
)
)
Next up, we define our clean prompt and our corrupted prompt. As prompts may be associated with many different feature circuits (i.e., circuits responsible for IOI, deciding if the language is English, or prompt refusal), choosing a counterfactual prompt with only changes directly related your feature of interest is essential.
Here, we switch the name of the repeated subject, thus swapping out the indirect object for our IOI task:
[7]:
clean_prompt = "After John and Mary went to the store, Mary gave a bottle of milk to"
corrupted_prompt = (
"After John and Mary went to the store, John gave a bottle of milk to"
)
We then use the tokenizer on the two words of interest (“John” and “Mary”) to find the token that represents them. That way we can grab the prediction for these two tokens and compare. Because our prompts don’t end in a space, make sure to add a space before each word (i.e., the combined space + word token is what we’re looking for).
[8]:
correct_index = model.tokenizer(" John")["input_ids"][0] # includes a space
incorrect_index = model.tokenizer(" Mary")["input_ids"][0] # includes a space
print(f"' John': {correct_index}")
print(f"' Mary': {incorrect_index}")
' John': 1757
' Mary': 5335
Patching Experiment#
Now we can run the actual patching intervention! What does this even mean?
We now have two prompts, a “clean” one and a “corrupted” one. Intuitively, the model output for each of these prompts should be different: we’d expect the model to answer “John” for the clean prompt and “Mary” for the corrupted prompt.
In this experiment, we run the model with the clean prompt as an input and then (1) get each layer’s output value (i.e., residual stream) and (2) calculate the logit difference between the correct and incorrect answers for this run. Next, we calculate the logit difference between the correct and incorrect answers for the corrupted prompt.
Step 1: Clean Run#
First, we run the model with the clean prompt:
"After John and Mary went to the store, Mary gave a bottle of milk to"
During this clean run, we collect the final output of each layer. We also record the logit difference in the final model output between the correct answer token " John" and the incorrect token " Mary".
[9]:
N_LAYERS = len(model.transformer.h)
# Clean run
with model.trace(clean_prompt) as tracer:
clean_tokens = tracer.invoker.inputs[0][0]['input_ids'][0]
# Get hidden states of all layers in the network.
# We index the output at 0 because it's a tuple where the first index is the hidden state.
clean_hs = [
model.transformer.h[layer_idx].output[0].save()
for layer_idx in range(N_LAYERS)
]
# Get logits from the lm_head.
clean_logits = model.lm_head.output
# Calculate the difference between the correct answer and incorrect answer for the clean run and save it.
clean_logit_diff = (
clean_logits[0, -1, correct_index] - clean_logits[0, -1, incorrect_index]
).save()
Step 2: Corrupted Run#
Next, we run the model using the corrupted input prompt:
"After John and Mary went to the store, John gave a bottle of milk to"
During this corrupted run, we collect the logit difference in the final model output between the correct and incorrect answer tokens
Note: because we are testing changes induced by the corrupted prompt, the target answers remain the same as in the clean run. That is, the correct token is still " John" and the incorrect token is still " Mary".
[10]:
# Corrupted run
with model.trace(corrupted_prompt) as tracer:
corrupted_logits = model.lm_head.output
# Calculate the difference between the correct answer and incorrect answer for the corrupted run and save it.
corrupted_logit_diff = (
corrupted_logits[0, -1, correct_index]
- corrupted_logits[0, -1, incorrect_index]
).save()
Step 3: Activation Patching Intervention#
Finally, we perform our activation patching procedure. For each token position in the clean prompt, we loop through all layers of the model. Within each layer, we run a forward pass using the corrupted prompt, and patch in the corresponding activation from our clean run at the given token position. We then collect the final output difference between the correct and incorrect answer tokens for each patched activation.
[11]:
# Activation Patching Intervention
ioi_patching_results = []
# Iterate through all the layers
for layer_idx in range(len(model.transformer.h)):
_ioi_patching_results = []
# Iterate through all tokens
for token_idx in range(len(clean_tokens)):
# Patching corrupted run at given layer and token
with model.trace(corrupted_prompt) as tracer:
# Apply the patch from the clean hidden states to the corrupted hidden states.
model.transformer.h[layer_idx].output[0][:, token_idx, :] = clean_hs[layer_idx][:, token_idx, :]
patched_logits = model.lm_head.output
patched_logit_diff = (
patched_logits[0, -1, correct_index]
- patched_logits[0, -1, incorrect_index]
)
# Calculate the improvement in the correct token after patching.
patched_result = (patched_logit_diff - corrupted_logit_diff) / (
clean_logit_diff - corrupted_logit_diff
)
_ioi_patching_results.append(patched_result.item().save())
ioi_patching_results.append(_ioi_patching_results)
Note: Optimize workflow with NNsight batching#
Although we broke up the workflow for ease of understanding, we can use nnsight to further speed up computation.
Thanks to nnsight, the whole experiment can happen in one forward pass by breaking up inputs into multiple invocation calls and batching them.
[ ]:
N_LAYERS = len(model.transformer.h)
# Enter nnsight tracing context
with model.trace() as tracer:
# Clean run
with tracer.invoke(clean_prompt) as invoker:
clean_tokens = invoker.inputs[0][0]['input_ids'][0]
# No need to call .save() as we don't need the values after the run, just within the experiment run.
clean_hs = [
model.transformer.h[layer_idx].output[0]
for layer_idx in range(N_LAYERS)
]
# Get logits from the lm_head.
clean_logits = model.lm_head.output
# Calculate the difference between the correct answer and incorrect answer for the clean run and save it.
clean_logit_diff = (
clean_logits[0, -1, correct_index] - clean_logits[0, -1, incorrect_index]
).save()
# Corrupted run
with tracer.invoke(corrupted_prompt) as invoker:
corrupted_logits = model.lm_head.output
# Calculate the difference between the correct answer and incorrect answer for the corrupted run and save it.
corrupted_logit_diff = (
corrupted_logits[0, -1, correct_index]
- corrupted_logits[0, -1, incorrect_index]
).save()
ioi_patching_results = []
# Iterate through all the layers
for layer_idx in range(len(model.transformer.h)):
_ioi_patching_results = []
# Iterate through all tokens
for token_idx in range(len(clean_tokens)):
# Patching corrupted run at given layer and token
with tracer.invoke(corrupted_prompt) as invoker:
# Apply the patch from the clean hidden states to the corrupted hidden states.
model.transformer.h[layer_idx].output[0][:, token_idx, :] = clean_hs[layer_idx][:, token_idx, :]
patched_logits = model.lm_head.output
patched_logit_diff = (
patched_logits[0, -1, correct_index]
- patched_logits[0, -1, incorrect_index]
)
# Calculate the improvement in the correct token after patching.
patched_result = (patched_logit_diff - corrupted_logit_diff) / (
clean_logit_diff - corrupted_logit_diff
)
_ioi_patching_results.append(patched_result.item().save())
ioi_patching_results.append(_ioi_patching_results)
Visualize Results#
Let’s define a function to plot our activation patching results.
[12]:
from nnsight.tracing.graph import Proxy
def plot_ioi_patching_results(model,
ioi_patching_results,
x_labels,
plot_title="Normalized Logit Difference After Patching Residual Stream on the IOI Task"):
ioi_patching_results = util.apply(ioi_patching_results, lambda x: x.value, Proxy)
fig = px.imshow(
ioi_patching_results,
color_continuous_midpoint=0.0,
color_continuous_scale="RdBu",
labels={"x": "Position", "y": "Layer","color":"Norm. Logit Diff"},
x=x_labels,
title=plot_title,
)
return fig
Let’s see how the patching intervention changes the logit difference! Let’s use a heatmap to examine how the logit difference changes after patching each layer’s output across token positions.
[14]:
print(f"Clean logit difference: {clean_logit_diff:.3f}")
print(f"Corrupted logit difference: {corrupted_logit_diff:.3f}")
clean_decoded_tokens = [model.tokenizer.decode(token) for token in clean_tokens]
token_labels = [f"{token}_{index}" for index, token in enumerate(clean_decoded_tokens)]
fig = plot_ioi_patching_results(model, ioi_patching_results,token_labels,"Patching GPT-2-small Residual Stream on IOI task")
fig.show()
Clean logit difference: 4.124
Corrupted logit difference: -2.272
In the above plot, we see that patching the clean residual stream into the corrupted model does not change much in the final token difference for input tokens 0-9. This is expected, as there is no difference in the clean vs. corrupted prompt for these tokens, so patching in the clean activations at this point shouldn’t change the model prediction.
However, when we get to token #10, “Mary”, where the subject is introduced for the second time, there is a sharp increase in output logit difference, indicating that the patch changes how the model predicts the outcome downstream, particularly for the earlier layers. There is also a transition in the middle layers of the network where the logit difference starts decreasing. We are thus seeing how the network is tracking information about the indirect object as the layers progress.
A similar but opposite effect is observed when the activations for the final prompt token are patched: the normalized logit difference increases after a transition period in the middle layers.
Limitations#
Although activation patching is an effective technique for circuit localization, it requires running a forward pass through the model for every patch, making it computationally expensive.
Attribution patching is an approximation of activation patching that helps scale the technique to larger experiments and models. See our attribution patching tutorial here to try it out!
Trying on a bigger model#
Although the original IOI experiment was performed on GPT-2 small, NDIF allows researchers to explore similar problems on largescale models!
Let’s see how the residual stream of Llama 3.1-8B contributes to the IOI task using activation patching with NDIF’s remote infrastructure.
Make sure you have obtained your NDIF API key and configured your workspace for remote execution.
[15]:
from nnsight import CONFIG
if is_colab:
# include your HuggingFace Token and NNsight API key on Colab secrets
from google.colab import userdata
NDIF_API = userdata.get('NDIF_API')
HF_TOKEN = userdata.get('HF_TOKEN')
CONFIG.set_default_api_key(NDIF_API)
!huggingface-cli login -token HF_TOKEN
clear_output()
[17]:
import torch
import nnsight
from nnsight import LanguageModel
[25]:
# Load model
llm = LanguageModel("meta-llama/Meta-Llama-3.1-8B")
print(llm)
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
(generator): Generator(
(streamer): Streamer()
)
)
Define some IOI prompts. Each of these prompts can be used as a ‘clean’ and as a ‘corrupted’ prompt, as each prompt has a related corrupted version with the IO switched out.
[26]:
prompts = [
"When Lisa and Sarah went to the cinema, Lisa gave the ticket to",
"When Lisa and Sarah went to the cinema, Sarah gave the ticket to"
]
Define the answers to these prompts, formatted as (correct, incorrect)
[27]:
answers = [
(" Sarah", " Lisa"),
(" Lisa", " Sarah")
]
[28]:
# Tokenize clean and corrupted inputs:
clean_tokens = llm.tokenizer(prompts, return_tensors="pt")["input_ids"]
corrupted_tokens = clean_tokens[
[(i + 1 if i % 2 == 0 else i - 1) for i in range(len(clean_tokens))]
]
# Tokenize answers for each prompt:
answer_token_indices = [
[llm.tokenizer(answers[i][j])["input_ids"][1] for j in range(2)]
for i in range(len(answers))
]
print("answer_tokens = " , answer_token_indices)
answer_tokens = [[21077, 29656], [29656, 21077]]
The residual stream isn’t the only model component you can apply activation patching on: let’s try patching Llama’s attention heads to see how they influence the IOI task! Here, we apply our patching intervention on the attention output, o_proj.output in Llama models.
Because the multihead attention of Llama models are stored in a projection matrix containing all attention heads, we will need to resize the tensor to reveal individual attention head contributions. The einops library is a handy way to resize tensors.
[29]:
import einops
Okay, now let’s apply our three activation patching steps to our attention heads during an IOI task.
[44]:
# Enter nnsight tracing context
N_LAYERS = len(llm.model.layers)
batch = 1
seq = len(prompts[0]) #15 length of input tokens
N_HEADS = 32 #32 attention heads
D_MODEL = int(4096) #4096 size of model hidden
D_HEADS = int(D_MODEL/N_HEADS) #128 size of attention head
ioi_patching_results_all = []
prompt_id = 0
corrupt_id = (prompt_id + 1 if prompt_id % 2 == 0 else prompt_id - 1)
with llm.trace(remote = True) as tracer:
# STEP 1: Clean run, grab clean activations for each attention head
with tracer.invoke(prompts[prompt_id]) as invoker:
clean_tokens = invoker.inputs[0][0]['input_ids'][0]
# Get clean attention output for later patching
z_hs = {}
for layer_idx in range(N_LAYERS):
# attention output for llama models needs to be reshaped to look at individual heads
z = llm.model.layers[layer_idx].self_attn.o_proj.input # dimensions [1x15x4096] [batch x seq x D_MODEL]
z_reshaped = einops.rearrange(z, 'b s (nh dh) -> b s nh dh',nh=32)
for head_idx in range(N_HEADS):
z_hs[layer_idx,head_idx] = z_reshaped[:,:,head_idx,:]
# Get logits from the lm_head.
clean_logits = llm.lm_head.output
clean_logit_diff = (
clean_logits[0, -1, answer_token_indices[prompt_id][0]] - clean_logits[0, -1, answer_token_indices[prompt_id][1]]
).save()
# STEP 2: Corrupted run, grab corrupted logits for later comparison.
with tracer.invoke(prompts[corrupt_id]) as invoker:
corrupted_tokens = invoker.inputs[0][0]['input_ids'][0]
corrupted_logits = llm.lm_head.output
# Calculate the difference between the correct answer and incorrect answer for the corrupted run and save it.
corrupted_logit_diff = (
corrupted_logits[0, -1, answer_token_indices[prompt_id][0]] - corrupted_logits[0, -1, answer_token_indices[prompt_id][1]]
).save()
# STEP 3: Patching runs, apply 'clean' model state at each layer and head,
ioi_patching_results = []
# Patching: Iterate through all the layers
for layer_idx in range(len(llm.model.layers)):
_ioi_patching_results = []
# Iterate through all attention heads
for head_idx in range(N_HEADS):
# Patching corrupted run at given layer and token
with tracer.invoke(prompts[corrupt_id]) as invoker:
# Apply the patch from the clean hidden states to the corrupted hidden state for given layer and head.
z_corrupt = llm.model.layers[layer_idx].self_attn.o_proj.input
z_corrupt = einops.rearrange(z_corrupt, 'b s (nh dh) -> b s nh dh',nh=32)
z_corrupt[:,:,head_idx,:] = z_hs[layer_idx,head_idx]
z_corrupt = einops.rearrange(z_corrupt, 'b s nh dh -> b s (nh dh)', nh=32)
llm.model.layers[layer_idx].self_attn.o_proj.input = z_corrupt
patched_logits = llm.lm_head.output
patched_logit_diff = (
patched_logits[0, -1, answer_token_indices[prompt_id][0]]
- patched_logits[0, -1, answer_token_indices[prompt_id][1]]
)
# Calculate the improvement in the correct token after patching.
patched_result = (patched_logit_diff - corrupted_logit_diff) / (
clean_logit_diff - corrupted_logit_diff
)
_ioi_patching_results.append(patched_result.item().save())
ioi_patching_results.append(_ioi_patching_results)
2025-02-04 11:32:56,559 750987cd-29a3-4679-b53f-db294082eeae - RECEIVED: Your job has been received and is waiting approval.
2025-02-04 11:32:56,744 750987cd-29a3-4679-b53f-db294082eeae - APPROVED: Your job was approved and is waiting to be run.
2025-02-04 11:32:59,440 750987cd-29a3-4679-b53f-db294082eeae - RUNNING: Your job has started running.
2025-02-04 11:33:10,401 750987cd-29a3-4679-b53f-db294082eeae - COMPLETED: Your job has been completed.
Downloading result: 100%|██████████| 13.8k/13.8k [00:00<00:00, 1.68MB/s]
Let’s use the same plotting function from earlier to visualize how patching the Llama-3.1-8B attention heads influenced model output during the IOI task.
[45]:
print(f"Clean logit difference: {clean_logit_diff.value:.3f}")
print(f"Corrupted logit difference: {corrupted_logit_diff.value:.3f}") # why do I still need .value?
print(ioi_patching_results)
x_labels = [f"Head {i}" for i in range(N_HEADS)]
fig2 = plot_ioi_patching_results(llm, ioi_patching_results,x_labels,"Patching Llama Attention Heads on IOI task")
fig2.show()
Clean logit difference: 5.125
Corrupted logit difference: -4.500
[[0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.006500244140625, 0.01300048828125, 0.01300048828125, -0.006500244140625, 0.0, -0.006500244140625, 0.01300048828125, 0.006500244140625, -0.006500244140625, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.006500244140625, -0.006500244140625, 0.0, 0.0, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.006500244140625], [0.006500244140625, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.01953125, 0.0, -0.006500244140625, 0.01300048828125, 0.01953125, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.0, 0.01300048828125, 0.0, 0.0, 0.006500244140625, 0.006500244140625, 0.0, 0.01300048828125, -0.006500244140625, 0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.01300048828125, 0.006500244140625, 0.006500244140625], [0.006500244140625, 0.01300048828125, -0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.0, -0.006500244140625, 0.006500244140625, -0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.006500244140625, 0.0, -0.006500244140625, 0.01300048828125, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.006500244140625, 0.006500244140625, -0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.006500244140625], [0.0, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, 0.006500244140625, 0.01300048828125, 0.01300048828125, -0.006500244140625, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.01300048828125], [0.006500244140625, 0.0, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.11669921875, 0.01300048828125, 0.01300048828125, 0.006500244140625, -0.006500244140625, 0.0, 0.0, 0.0, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.006500244140625], [0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.006500244140625, -0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.0, 0.01300048828125, 0.01300048828125, 0.01953125, 0.0, 0.0, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.0], [0.0, 0.006500244140625, 0.0, 0.0, 0.01953125, 0.0, 0.006500244140625, -0.006500244140625, 0.006500244140625, 0.006500244140625, -0.006500244140625, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.006500244140625, -0.006500244140625, 0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.01300048828125, -0.006500244140625, 0.0, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.0], [0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.006500244140625, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, -0.006500244140625, -0.006500244140625, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.006500244140625, -0.006500244140625, 0.006500244140625, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.01300048828125], [-0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, -0.006500244140625, 0.006500244140625, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, -0.01300048828125, 0.0, -0.006500244140625, 0.006500244140625, 0.0, 0.0, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.01300048828125, 0.006500244140625], [0.01300048828125, 0.006500244140625, 0.0, 0.006500244140625, 0.006500244140625, 0.006500244140625, -0.006500244140625, 0.006500244140625, -0.006500244140625, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.006500244140625, 0.0, 0.0, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.0, 0.0, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.0], [0.01953125, -0.01953125, -0.01300048828125, -0.006500244140625, 0.0, 0.0, 0.0, 0.0, 0.0, 0.01953125, -0.006500244140625, 0.01300048828125, 0.006500244140625, 0.01953125, 0.006500244140625, 0.0, 0.0, 0.006500244140625, 0.0, 0.0, 0.006500244140625, 0.01953125, 0.0, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, 0.006500244140625, 0.006500244140625], [0.006500244140625, 0.0, 0.006500244140625, 0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.01300048828125, -0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.0, 0.006500244140625, 0.0, 0.01300048828125, 0.0, 0.01953125, 0.0, 0.0260009765625, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.01300048828125], [0.006500244140625, 0.0, 0.0, 0.0, 0.0, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.0, 0.0260009765625, 0.006500244140625, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.006500244140625, 0.0, -0.006500244140625, 0.0, 0.0, 0.01953125, 0.0, 0.01953125, 0.01300048828125, 0.006500244140625, 0.0, 0.0, 0.006500244140625, 0.006500244140625], [0.0, 0.0, 0.0, 0.0, 0.006500244140625, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, 0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.0, 0.0], [0.0, 0.01953125, 0.0, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.052001953125, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.0, 0.0, 0.0, 0.06494140625, 0.01300048828125, 0.006500244140625, 0.078125, 0.0, 0.0260009765625, 0.0, 0.006500244140625, 0.0, 0.0, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.0, 0.006500244140625, 0.01300048828125], [0.0, 0.0, 0.01300048828125, -0.006500244140625, 0.01300048828125, 0.01300048828125, -0.006500244140625, 0.006500244140625, 0.01953125, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, 0.0, 0.1298828125, 0.0, 0.0, 0.0, 0.01953125, 0.0, 0.0, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.006500244140625], [-0.01953125, 0.0712890625, 0.0390625, -0.01300048828125, 0.006500244140625, 0.01300048828125, 0.0, 0.0, 0.0, 0.006500244140625, 0.01300048828125, -0.006500244140625, 0.01953125, 0.01300048828125, 0.0, 0.0, -0.06494140625, 0.0260009765625, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.0, 0.09716796875, 0.0, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.032470703125, 0.006500244140625, -0.01953125, 0.0], [0.01300048828125, 0.006500244140625, 0.0, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.052001953125, -0.01300048828125, 0.0, 0.17578125, 0.01300048828125, 0.0, 0.006500244140625, 0.0], [0.0, 0.0, 0.0, 0.01300048828125, 0.0, 0.0, 0.0, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.006500244140625, 0.006500244140625, 0.01300048828125, 0.0, -0.006500244140625, 0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.0260009765625, -0.006500244140625, 0.11669921875, 0.01953125, 0.0], [0.01300048828125, 0.0, 0.0, -0.01300048828125, 0.006500244140625, 0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, -0.032470703125, 0.01300048828125, 0.01300048828125, 0.0908203125, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, 0.0], [0.0, 0.0, 0.0, 0.0260009765625, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, 0.0, -0.10400390625, 0.078125, -0.2333984375, 0.006500244140625, 0.01300048828125, 0.006500244140625, 0.0, 0.0, -0.006500244140625, 0.01300048828125, 0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.0, 0.006500244140625, 0.01300048828125, 0.0, 0.0, 0.0], [0.0, 0.0, 0.032470703125, -0.01953125, 0.0, 0.0, 0.0, 0.0, -0.01300048828125, 0.006500244140625, 0.0390625, 0.01300048828125, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, -0.006500244140625, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, 0.0], [0.0, 0.0, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.0, 0.01300048828125, 0.0, 0.032470703125, 0.0, -0.006500244140625, 0.0, 0.01300048828125, 0.0, -0.01953125, 0.181640625, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, 0.006500244140625, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0260009765625, 0.0], [0.0, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.0, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.01953125, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.006500244140625], [0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.0, 0.0, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, 0.006500244140625, 0.0, 0.0, 0.0, 0.01300048828125, 0.0, 0.0, -0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.0390625, 0.0, 0.0, 0.01300048828125, 0.0], [0.0, 0.0, 0.0, 0.0, 0.006500244140625, 0.006500244140625, -0.006500244140625, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.1103515625, 0.006500244140625, 0.006500244140625, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.0, 0.006500244140625, 0.01300048828125, 0.0, 0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.0, 0.0, 0.006500244140625, 0.0], [-0.006500244140625, 0.01300048828125, -0.006500244140625, 0.01953125, 0.0, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.006500244140625, -0.006500244140625, 0.1298828125, -0.006500244140625, 0.01300048828125, -0.078125, 0.0, 0.0, 0.006500244140625, 0.0, 0.01300048828125, 0.0, 0.006500244140625, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.0, -0.006500244140625, 0.0, 0.0, 0.01300048828125], [0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.006500244140625, -0.006500244140625, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.01300048828125, 0.162109375, 0.01953125, 0.0260009765625, 0.006500244140625, 0.01300048828125, 0.0, 0.0, 0.0, 0.01300048828125, 0.0, 0.0, 0.01300048828125], [0.01300048828125, 0.0, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.006500244140625, 0.0, 0.006500244140625, -0.058349609375, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.006500244140625, 0.01300048828125, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, 0.0], [0.01300048828125, 0.0, 0.0, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.032470703125, 0.0, -0.0908203125, 0.0390625, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125], [-0.006500244140625, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01953125, 0.0908203125, 0.01300048828125, -0.006500244140625, 0.01300048828125, 0.01300048828125, 0.0, 0.0, 0.01300048828125, 0.0, 0.01300048828125, 0.0, 0.0, -0.0712890625, 0.01953125, 0.0260009765625, 0.006500244140625, 0.0, 0.01953125, 0.01953125], [-0.006500244140625, 0.01953125, -0.01300048828125, 0.0260009765625, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.01300048828125, 0.0, -0.006500244140625, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.01300048828125, -0.006500244140625, 0.0, 0.006500244140625, 0.0, 0.0, 0.01300048828125, 0.01300048828125, 0.0, 0.0]]